
Announcing the Evolution: Qwen1.5 to Qwen2
After months of dedicated efforts, we are thrilled to unveil the next generation of our AI models: Qwen2. Here’s what’s new and improved:
Five New Model Sizes:
- Qwen2-0.5B
- Qwen2-1.5B
- Qwen2-7B
- Qwen2-57B-A14B
- Qwen2-72B
Multilingual Capabilities: Qwen2 models are now trained on data in 27 additional languages, expanding beyond English and Chinese to support a more diverse and global user base.
State-of-the-Art Performance: Our models have demonstrated cutting-edge performance across a wide range of benchmark evaluations, showcasing their advanced capabilities and reliability.
Enhanced Coding and Mathematics: Qwen2 models exhibit significantly improved performance in coding and mathematical problem-solving, making them invaluable tools for developers and researchers.
Extended Context Length: Qwen2-7B-Instruct and Qwen2-72B-Instruct models now support extended context lengths up to 128K tokens. This allows for more comprehensive and detailed processing of large datasets, enhancing the models’ usability for complex tasks.
These advancements mark a substantial leap in our AI technology, providing users with more powerful, versatile, and accurate tools. We are excited for you to experience the enhanced capabilities of Qwen2.
Model Information: Qwen2 Series
The Qwen2 series encompasses both base and instruction-tuned models available in five different sizes. These sizes are designed to cater to a wide range of applications and computational needs. Below is an overview of the key information for each model:
- Qwen2-0.5B:
- Parameters: 0.5 billion
- Purpose: Ideal for lightweight applications requiring fast processing and lower computational resources.
- Qwen2-1.5B:
- Parameters: 1.5 billion
- Purpose: Suitable for more complex tasks that benefit from increased computational power and enhanced accuracy.
- Qwen2-7B:
- Parameters: 7 billion
- Purpose: Balances performance and efficiency, making it well-suited for a variety of standard AI tasks.
- Qwen2-57B-A14B:
- Parameters: 57 billion (augmented by A14B technology)
- Purpose: Designed for high-performance requirements, particularly in demanding computational environments and large-scale applications.
- Qwen2-72B:
- Parameters: 72 billion
- Purpose: The most powerful model in the series, ideal for intensive tasks that demand maximum accuracy and computational capacity.
Key Features:
- Multilingual Training: Each model has been trained on data from 27 additional languages, providing robust support for diverse linguistic applications beyond just English and Chinese.
- Benchmark Performance: The Qwen2 models achieve state-of-the-art results across a wide array of benchmark tests, affirming their advanced capabilities.
- Enhanced Coding and Mathematics: Significant improvements in these areas make the Qwen2 series particularly valuable for technical and scientific applications.
- Extended Context Length: Qwen2-7B-Instruct and Qwen2-72B-Instruct models support context lengths up to 128K tokens, allowing for the processing of extensive and complex datasets.
These enhancements position the Qwen2 series as a versatile and powerful solution for a broad spectrum of AI needs, from simple queries to advanced computational tasks.
Enhancements in Qwen2 Series
Group Query Attention (GQA)
In the previous Qwen1.5 series, only the Qwen1.5-32B and Qwen1.5-110B models utilized Group Query Attention (GQA). In the Qwen2 series, GQA has been integrated across all model sizes. This integration significantly enhances inference speed and reduces memory usage, making the models more efficient and scalable. For smaller models, tying embedding techniques are preferred over large sparse embeddings, as they take up a substantial portion of the total model parameters, optimizing performance and resource management.
Extended Context Length
All base language models in the Qwen2 series have been pretrained on datasets with a context length of 32K tokens. These models demonstrate satisfactory extrapolation capabilities up to 128K tokens, as evidenced by Perplexity (PPL) evaluations. However, instruction-tuned models require more than just PPL evaluation; they must accurately understand and complete tasks with long context lengths.
In this regard, the context length capabilities of the instruction-tuned models have been rigorously evaluated using the “Needle in a Haystack” task. Notably, when augmented with YARN, the Qwen2-7B-Instruct and Qwen2-72B-Instruct models exhibit an impressive ability to handle context lengths extending up to 128K tokens, ensuring precise task completion and robust understanding of extensive contexts.
Multilingual Competence
Significant efforts have been made to enhance both the volume and quality of pretraining and instruction-tuning datasets, especially in terms of linguistic diversity. While large language models inherently possess the ability to generalize to various languages, the Qwen2 series explicitly includes training on 27 additional languages beyond English and Chinese. This deliberate inclusion strengthens the models’ multilingual capabilities, ensuring better performance and understanding across a diverse range of languages.
Key Model Information

The Qwen2 series includes both base and instruction-tuned models available in five sizes, each tailored for different applications and computational needs:
- Qwen2-0.5B
- Parameters: 0.5 billion
- Purpose: Ideal for lightweight applications requiring fast processing and lower computational resources.
- Qwen2-1.5B
- Parameters: 1.5 billion
- Purpose: Suitable for more complex tasks that benefit from increased computational power and enhanced accuracy.
- Qwen2-7B
- Parameters: 7 billion
- Purpose: Balances performance and efficiency, making it well-suited for a variety of standard AI tasks.
- Qwen2-57B-A14B
- Parameters: 57 billion (augmented by A14B technology)
- Purpose: Designed for high-performance requirements, particularly in demanding computational environments and large-scale applications.
- Qwen2-72B
- Parameters: 72 billion
- Purpose: The most powerful model in the series, ideal for intensive tasks that demand maximum accuracy and computational capacity.
Linguistic Diversity and Code-Switching in the Qwen2 Series
Regional and Linguistic Coverage
The Qwen2 series demonstrates a significant leap in linguistic diversity, encompassing an extensive range of languages across multiple regions. This broad linguistic spectrum ensures that the models can cater to diverse global audiences, enhancing their applicability and relevance.
- Western Europe:
- Languages: German, French, Spanish, Portuguese, Italian, Dutch
- Eastern & Central Europe:
- Languages: Russian, Czech, Polish
- Middle East:
- Languages: Arabic, Persian, Hebrew, Turkish
- Eastern Asia:
- Languages: Japanese, Korean
- South-Eastern Asia:
- Languages: Vietnamese, Thai, Indonesian, Malay, Lao, Burmese, Cebuano, Khmer, Tagalog
- Southern Asia:
- Languages: Hindi, Bengali, Urdu
Enhanced Multilingual Capabilities
To bolster the Qwen2 models’ multilingual competencies, significant efforts were directed towards augmenting both the volume and quality of pretraining and instruction-tuning datasets. These datasets now include 27 additional languages beyond English and Chinese, ensuring a more comprehensive linguistic foundation. This enhancement is critical as large language models inherently possess the capacity to generalize across languages, and the explicit inclusion of diverse languages further strengthens this ability.
Addressing Code-Switching
Code-switching, the practice of alternating between two or more languages within a conversation or text, poses a unique challenge in multilingual evaluations. Recognizing its prevalence, particularly in regions with high linguistic diversity, the Qwen2 series has focused on improving the models’ proficiency in handling this phenomenon.
- Enhanced Proficiency:
- Through rigorous evaluations and fine-tuning, the Qwen2 models exhibit a notable enhancement in managing code-switching scenarios. This improvement is critical for maintaining context and coherence in multilingual communications.
- Evaluation Methodology:
- The models were subjected to prompts designed to induce code-switching across languages. The evaluations confirmed a substantial reduction in issues typically associated with code-switching, indicating that the Qwen2 models can more effectively navigate multilingual environments.
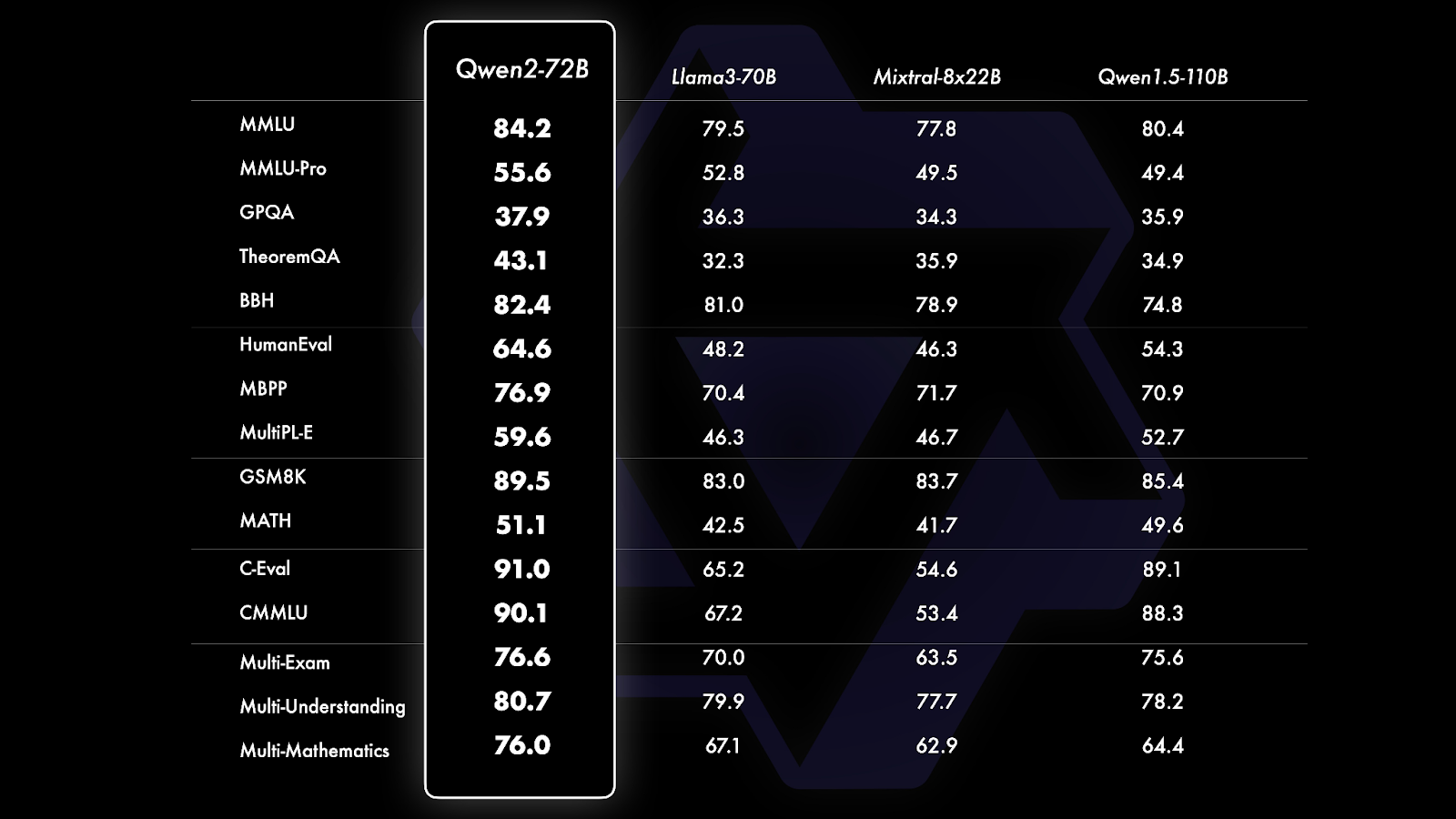
Performance Enhancements in Qwen2-72B Model
Overview of Comparative Assessments
Recent evaluations of the Qwen2-72B model, part of the Qwen2 series, have revealed substantial performance enhancements compared to its predecessor, Qwen1.5, particularly in large-scale models with 70 billion+ parameters. The focus of this assessment is the large-size Qwen2-72B model, which showcases significant improvements across various capabilities.
Evaluation Metrics
The Qwen2-72B model has been rigorously evaluated against state-of-the-art open models in several key areas:
- Natural Language Understanding: The ability to comprehend and process natural language inputs.
- Knowledge Acquisition: The capacity to assimilate and utilize vast amounts of information.
- Coding Proficiency: The effectiveness in understanding and generating code.
- Mathematical Skills: The ability to perform and solve complex mathematical problems.
- Multilingual Abilities: The proficiency in understanding and generating content across multiple languages.
Superior Performance
Benefiting from meticulously curated datasets and optimized training methods, Qwen2-72B exhibits superior performance compared to leading models, such as Llama-3-70B. Notably, Qwen2-72B surpasses its predecessor, Qwen1.5-110B, despite having fewer parameters. This is a testament to the advancements in training techniques and data quality employed in the development of the Qwen2 series.
Key Highlights
- Enhanced Capabilities: Qwen2-72B demonstrates improved natural language understanding, making it more adept at processing and generating human language.
- Advanced Knowledge Integration: The model shows a higher capacity for knowledge acquisition, enabling it to provide more accurate and contextually relevant information.
- Improved Coding and Mathematical Proficiency: Qwen2-72B excels in coding tasks and mathematical problem-solving, making it a valuable tool for technical applications.
- Multilingual Mastery: With enhanced support for multiple languages, Qwen2-72B can effectively handle diverse linguistic inputs and outputs, broadening its usability.
Enhancing Qwen’s Intelligence through Advanced Post-Training
Overview of Post-Training Enhancements
Following extensive large-scale pre-training, we undertake a rigorous post-training process to further refine Qwen’s intelligence, bringing it closer to human-like understanding and performance. This phase is crucial for enhancing the model’s capabilities across a wide range of areas, including coding, mathematics, reasoning, instruction-following, and multilingual understanding. Additionally, it aligns the model’s outputs with human values, ensuring they are helpful, honest, and harmless.
Key Focus Areas in Post-Training
- Advanced Capabilities Enhancement:
- Coding: Utilizing execution feedback to refine coding skills, ensuring accurate and efficient code generation.
- Mathematics: Implementing rejection sampling techniques to improve mathematical reasoning and problem-solving abilities.
- Reasoning and Instruction-Following: Enhancing logical reasoning and the ability to follow complex instructions through targeted training strategies.
- Multilingual Understanding: Expanding the model’s language comprehension to include a diverse set of languages, facilitating better multilingual communication.
- Alignment with Human Values:
- Ethical AI: Ensuring outputs are aligned with principles of honesty, helpfulness, and harmlessness through careful calibration and testing.
- Scalable Training: Employing minimal human annotation while maximizing training efficiency to achieve scalable, high-quality results.
Automated Alignment Strategies
To achieve high-quality, reliable, and diverse training data, we utilize various automated alignment strategies:
- Rejection Sampling for Mathematics: Filtering out incorrect solutions to refine mathematical capabilities.
- Execution Feedback for Coding and Instruction-Following: Using real-time feedback to correct and enhance performance in coding tasks and instruction adherence.
- Back-Translation for Creative Writing: Ensuring the creative outputs are accurate and contextually appropriate through iterative translation checks.
- Scalable Oversight for Role-Play: Managing and improving role-play scenarios with automated oversight to ensure engaging and accurate interactions.
Training Techniques Employed
Our post-training phase incorporates a combination of advanced training methodologies:
- Supervised Fine-Tuning: Leveraging human-annotated data to fine-tune the model’s responses.
- Reward Model Training: Using reward-based systems to guide the model towards desired outcomes.
- Online DPO (Differentiable Policy Optimization) Training: Continuously updating the model with real-time data to enhance decision-making and performance.
- Online Merging Optimizer: A novel approach to minimize the alignment tax, ensuring efficient integration of training updates.
Outcomes of Post-Training
The collective efforts in post-training have significantly boosted the intelligence and capabilities of our models. These enhancements are reflected in improved performance across various benchmarks and real-world applications, as detailed in the accompanying performance table.
Comprehensive Evaluation of Qwen2-72B-Instruct
Overview of Evaluation
The Qwen2-72B-Instruct model has been rigorously evaluated across 16 benchmarks spanning various domains, demonstrating a remarkable balance between enhanced capabilities and alignment with human values. This evaluation underscores the model’s significant advancements over its predecessor and its competitive standing against other state-of-the-art models.
Key Performance Highlights
- Superior Benchmark Performance:
- Qwen2-72B-Instruct vs. Qwen1.5-72B-Chat: Qwen2-72B-Instruct significantly outperforms the Qwen1.5-72B-Chat model across all evaluated benchmarks, highlighting substantial improvements in model capability and efficiency.
- Comparison with Llama-3-70B-Instruct: Qwen2-72B-Instruct achieves competitive performance levels comparable to the Llama-3-70B-Instruct model, demonstrating its robustness and versatility in various tasks.
- Advancements in Smaller Models:
- State-of-the-Art Performance: The smaller Qwen2 models also exhibit superior performance compared to state-of-the-art models of similar or larger sizes. This highlights the efficiency and advanced capabilities of the Qwen2 architecture.
- Qwen2-7B-Instruct: This model, in particular, shows significant advantages across benchmarks, especially excelling in coding tasks and metrics related to Chinese language proficiency.
Detailed Benchmark Analysis
- Coding Proficiency: Qwen2-72B-Instruct demonstrates outstanding performance in coding benchmarks, showcasing advanced capabilities in understanding and generating programming code efficiently and accurately.
- Multilingual Competence: The model excels in benchmarks related to Chinese language tasks, reflecting its robust multilingual understanding and ability to handle diverse linguistic contexts effectively.
- Alignment with Human Values: In addition to technical capabilities, Qwen2-72B-Instruct aligns well with human values, ensuring that its outputs are not only accurate but also ethically sound and contextually appropriate.
Highlights: Enhancements in Coding and Mathematics
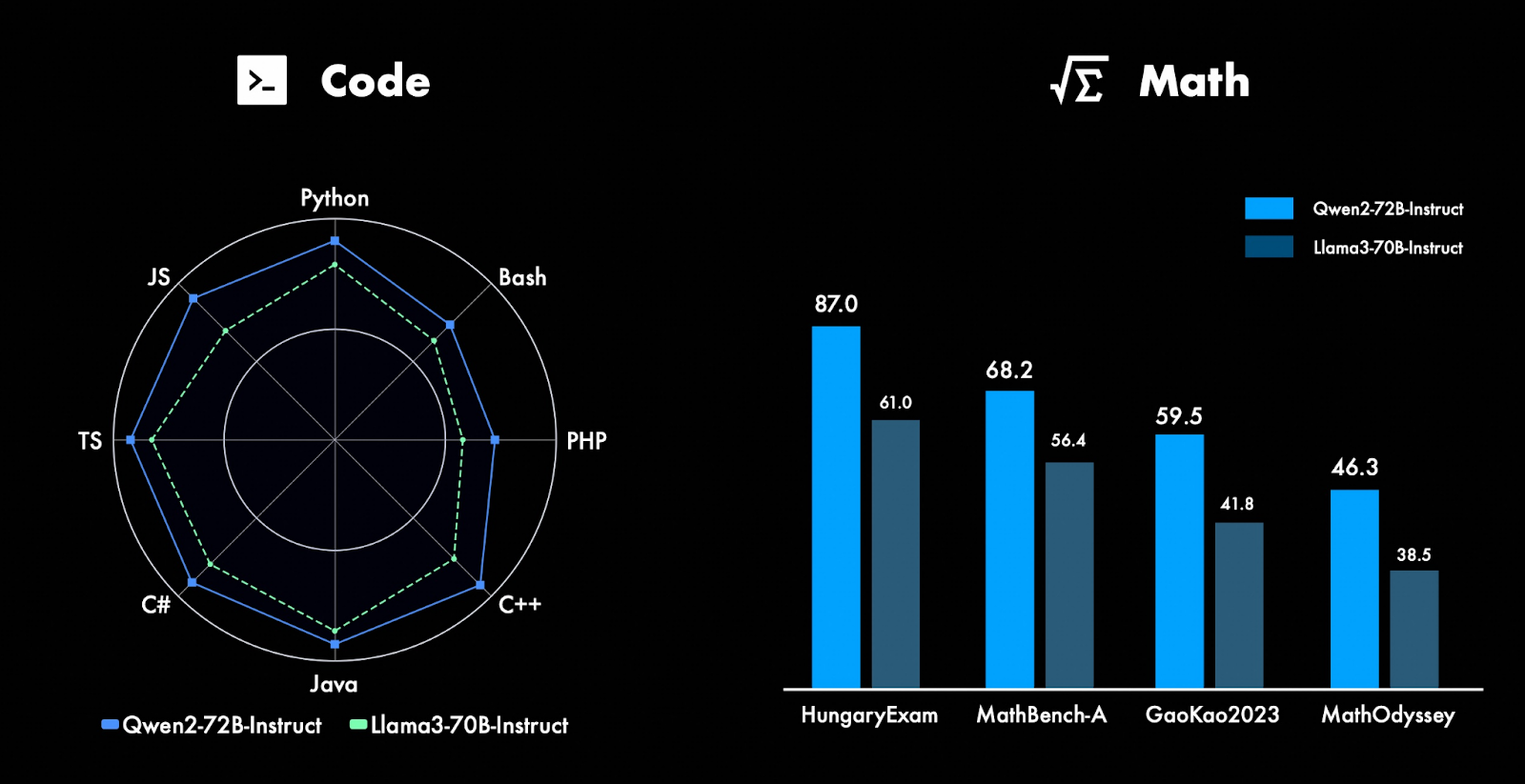
Advanced Capabilities in Coding
We have continually focused on advancing the capabilities of Qwen, with particular attention to coding. By integrating the extensive code training experience and data from CodeQwen1.5, we have achieved remarkable improvements in Qwen2-72B-Instruct across a wide range of programming languages. This integration has enhanced the model’s ability to understand, generate, and debug code efficiently.
- Enhanced Programming Language Support: Qwen2-72B-Instruct now supports a broader array of programming languages with improved accuracy and fluency. This makes it a powerful tool for developers working in diverse coding environments.
- Advanced Code Generation and Debugging: The model’s capabilities in code generation and debugging have been significantly boosted, allowing it to produce more reliable and efficient code snippets. This is particularly beneficial for complex programming tasks where precision is critical.
- Incorporation of CodeQwen1.5 Data: By leveraging the high-quality data from CodeQwen1.5, Qwen2-72B-Instruct can better understand the nuances of different programming languages, leading to more contextually accurate and functionally correct code outputs.
Superior Performance in Mathematics
Our efforts to enhance Qwen’s mathematical capabilities have also yielded significant results. By utilizing extensive and high-quality datasets, Qwen2-72B-Instruct demonstrates a robust ability to solve complex mathematical problems with greater accuracy and speed.
- High-Quality Mathematical Datasets: The use of comprehensive datasets has equipped Qwen2-72B-Instruct with a deeper understanding of mathematical concepts and problem-solving techniques.
- Improved Problem-Solving Skills: The model exhibits stronger capabilities in addressing a wide range of mathematical problems, from basic arithmetic to advanced calculus and algebra. This makes it an invaluable resource for educational purposes and professional applications alike.
- Enhanced Analytical Abilities: Qwen2-72B-Instruct’s improved analytical skills enable it to provide detailed solutions and explanations, helping users not only get the correct answers but also understand the underlying principles.
Long Context Understanding in Qwen2 Models

In the Qwen2 series, all instruction-tuned models have been extensively trained on contexts up to 32,000 tokens and further extrapolated to handle even longer contexts using advanced techniques like YARN and Dual Chunk Attention.
Exceptional Performance in Long Context Tasks
This models have demonstrated impressive capabilities in managing long-context tasks. The test results, particularly on the Needle in a Haystack benchmark, highlight their proficiency:
- Qwen2-72B-Instruct: This model excels in handling information extraction tasks within a context length of up to 128,000 tokens, making it the optimal choice for long text tasks when sufficient resources are available.
- Qwen2-7B-Instruct: It performs nearly flawlessly with contexts extending up to 128,000 tokens, showcasing robust long-context handling capabilities in a more resource-efficient package.
- Qwen2-57B-A14B-Instruct: This model manages contexts up to 64,000 tokens, balancing performance and resource requirements effectively.
- Qwen2-0.5B and Qwen2-1.5B: These smaller models are optimized for contexts of 32,000 tokens, providing strong performance for moderately long tasks.
Open-Sourced Agent for Large-Scale Document Processing
To complement the long-context models, we have also developed and open-sourced an agent solution capable of efficiently processing documents containing up to 1 million tokens. This solution is designed to handle extensive datasets and complex document structures, offering a powerful tool for large-scale text analysis.
Safety and Responsibility in Qwen2 Models

Ensuring safety and responsibility in AI responses is a critical aspect of model evaluation. The table below illustrates the proportion of harmful responses generated by various large models across four categories of multilingual unsafe queries: Illegal Activity, Fraud, Pornography, and Privacy Violations. The test data for these evaluations was sourced from Jailbreak and translated into multiple languages to provide a comprehensive assessment.
Evaluation Methodology
The evaluation focused on the following four categories of unsafe queries:
- Illegal Activity: Queries promoting or discussing illegal actions.
- Fraud: Queries involving deceitful practices intended to result in financial or personal gain.
- Pornography: Queries containing explicit sexual content.
- Privacy Violations: Queries that breach personal privacy or data protection norms.
Comparative Performance
The comparison included models such as Qwen2-72B-Instruct, GPT-4, and Mistral-8x22B. Notably, Llama-3 was excluded from the comparison due to its inadequate handling of multilingual prompts.
Key Findings:
- Qwen2-72B-Instruct vs. GPT-4: The Qwen2-72B-Instruct model demonstrated a performance in terms of safety comparable to that of GPT-4. This parity indicates that Qwen2-72B-Instruct is highly effective in managing and mitigating harmful responses across multiple languages.
- Qwen2-72B-Instruct vs. Mistral-8x22B: Significance testing (P-value analysis) revealed that Qwen2-72B-Instruct significantly outperforms the Mistral-8x22B model in terms of safety. This superior performance underscores Qwen2-72B-Instruct’s robust ability to handle unsafe queries responsibly.
Importance of Multilingual Safety
The capability to handle multilingual prompts safely is crucial for AI models deployed in diverse linguistic environments. Qwen2-72B-Instruct’s effectiveness across multiple languages highlights its suitability for global applications where ensuring the safe and responsible use of AI is paramount.
Developing with Qwen2: Comprehensive Integration and Support
The Qwen2 models are now available on Hugging Face and ModelScope. You can visit the model cards on these platforms for detailed usage instructions and to learn more about each model’s features, performance, and capabilities.
Broad Community Support
The development and enhancement of Qwen models have been significantly supported by a vibrant community. This collaboration spans various aspects of AI model development and deployment:
- Fine-tuning:
- Axolotl
- Llama-Factory
- Firefly
- Swift
- XTuner
- Quantization:
- AutoGPTQ
- AutoAWQ
- Neural Compressor
- Deployment:
- vLLM
- SGL
- SkyPilot
- TensorRT-LLM
- OpenVino
- TGI
- API Platforms:
- Together
- Fireworks
- OpenRouter
- Local Run:
- MLX
- Llama.cpp
- Ollama
- LM Studio
- Agent and Retrieval-Augmented Generation (RAG) Frameworks:
- LlamaIndex
- CrewAI
- OpenDevin
- Evaluation:
- LMSys
- OpenCompass
- Open LLM Leaderboard
- Model Training:
- Dolphin
- Openbuddy
This extensive ecosystem ensures that Qwen2 can be fine-tuned, quantized, deployed, and evaluated using a wide array of tools and platforms, making it a versatile choice for diverse AI applications.
Utilizing Third-Party Frameworks
To leverage Qwen2 models with third-party frameworks, please refer to the respective documentation provided by these tools. Additionally, our official documentation offers comprehensive guidance on how to integrate and utilize the models effectively within these ecosystems.
Acknowledging Contributions and Expanding Licensing for Qwen2
Community Contributions
The development of Qwen2 has been supported by numerous teams and individuals who have made significant contributions. While not every contributor is mentioned by name, we extend our heartfelt gratitude to all those who have supported this project. Your contributions have been invaluable, and we look forward to continuing our collaboration to advance the research and development of the open-source AI community.
Updated Licensing for Qwen2 Models
In a move to enhance openness and accessibility, we are updating the licenses for our models. Here’s a detailed overview of the changes:
- Qwen2-72B and Instruction-Tuned Models: These models will continue to use the original Qianwen License.
- Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, and Qwen2-57B-A14B: These models are now adopting the Apache 2.0 license.
The switch to the Apache 2.0 license for the majority of this models reflects our commitment to fostering greater openness and community engagement. This change is expected to accelerate the adoption and commercial use of this models worldwide, providing developers and businesses with more flexible and accessible tools to integrate advanced AI capabilities into their applications. SOURCE
Conclusion
The evolution from Qwen1.5 to Qwen2 marks a significant advancement in AI model capabilities. With five new model sizes, enhanced multilingual support, state-of-the-art performance in various benchmarks, and improved coding and mathematical proficiency, Qwen2 sets a new standard in AI technology. The integration of Group Query Attention (GQA) across all models and extended context length support up to 128K tokens further enhance their efficiency and scalability. The switch to the Apache 2.0 license for most models underscores a commitment to openness and accessibility, fostering greater community engagement and accelerating global adoption. These enhancements position as a versatile and powerful solution for diverse AI applications, advancing the field of open-source AI development.