
In the ongoing quest to harness artificial intelligence for enhancing daily life, Alibaba Group has thrown its hat into the ring alongside tech giants such as Meta, OpenAI, Microsoft, and Google. Alibaba recently unveiled its latest AI breakthrough, dubbed “EMO AI.” This cutting-edge model is a game-changer, with the ability to bring a single portrait photo to life by generating videos where the subject appears to talk or sing.
The world of image generation has been revolutionized by the advent of Diffusion Models, setting a new benchmark in the quest for realism. These models, including the likes of Sora and DALL-E 3, are built on the diffusion model framework and have significantly pushed the boundaries of what’s possible. Notably, their evolution has had a profound effect on video generation, particularly in the realm of creating dynamic visual stories. These advancements have paved the way for innovations in generating human-centric videos, such as talking heads, that strive to accurately mirror facial expressions in sync with audio inputs. Alibaba’s EMO AI represents a leap forward in this field, offering a unique approach by directly converting audio into expressive, realistic video animations without relying on 3D models. In this article, we delve into the specifics of Alibaba’s EMO AI and its potential to redefine video generation.

What is (Emote Portrait Alive ) EMO AI by Alibaba?
EMO AI by Alibaba represents a leap forward in artificial intelligence, addressing the limitations of traditional methods that often miss the mark in fully capturing the breadth of human expressions and the distinctiveness of individual facial characteristics. The solution proposed by Alibaba is EMO, a groundbreaking framework that pioneers a direct audio-to-video synthesis method. This approach eliminates the reliance on intermediary 3D models or facial landmarks, simplifying the process while enhancing output quality.
Short for Emote Portrait Alive, EMO AI is a product of the innovative minds at Alibaba Group. It merges the realms of AI and video production to unlock extraordinary possibilities. Here’s a glimpse into the capabilities that EMO AI brings to the table:
Bringing Portraits to Life
EMO AI from Alibaba Group is transforming how we see portraits, giving them the ability to come alive right before our eyes. This innovative AI technology can take a single still image of a person and turn it into a lifelike video, making the subject seem as though they’re engaging in conversation or breaking into song.
Direct Audio-to-Video Conversion:
What sets EMO AI apart from traditional methods is its unique ability to create videos directly from audio inputs. This bypasses the need for complex 3D modeling or the mapping of facial landmarks, ensuring smoother transitions between frames and maintaining the subject’s identity consistently across the animation. The result? Highly expressive and astonishingly realistic animations.
Bringing Emotions to Life:
EMO AI excels in translating the intricate relationship between sound and facial movements into dynamic and expressive videos. It’s not just about mimicking speech or song; it’s about capturing a full range of emotions, showcasing the diversity of human expressions and the uniqueness of individual facial characteristics.
Adaptable and Dynamic:
Whether it’s rendering a casual chat or a powerful vocal performance, EMO AI adapts to various scenarios with ease. Its versatility enables it to produce convincing videos of both speaking and singing, infusing them with a sense of realism and emotion that is truly remarkable.
EMO AI stands as a pioneering achievement in AI technology, seamlessly merging audio with visual elements to animate still portraits in a way that’s both fluid and full of expression. This leap forward opens up exciting possibilities, from personalizing digital interactions to revolutionizing how we experience digital content, making the once static images engage in lifelike dialogue or melodious tunes.
Also Read – Stable Diffusion 3: Leading the Charge in Next-Gen Creative AI
Training EMO AI
At the heart of Alibaba’s EMO AI lies a sophisticated framework designed to bring portraits to life through audio-driven animations. This framework synthesizes character head videos from mere images and audio clips, bypassing the need for complex intermediate steps. As a result, EMO AI delivers animations that maintain a high level of visual and emotional accuracy, perfectly in sync with the given audio. By integrating Diffusion Models, EMO AI adeptly captures the subtleties of human expressions and natural head movements, from the slight twitch of an eyebrow to the gentle nod of agreement.
The training process behind EMO is as extensive as it is meticulous. Researchers have compiled an expansive audio-video dataset that includes over 250 hours of footage and a staggering 150 million images. This dataset is incredibly diverse, encompassing everything from public speeches and segments from films and TV shows to singing performances across a variety of languages. Such a comprehensive collection of content ensures that EMO AI is well-equipped to recognize and replicate a broad spectrum of human emotions and vocal nuances, laying a solid groundwork for its exceptional performance.
The (Emote Portrait Alive)EMO AI Method
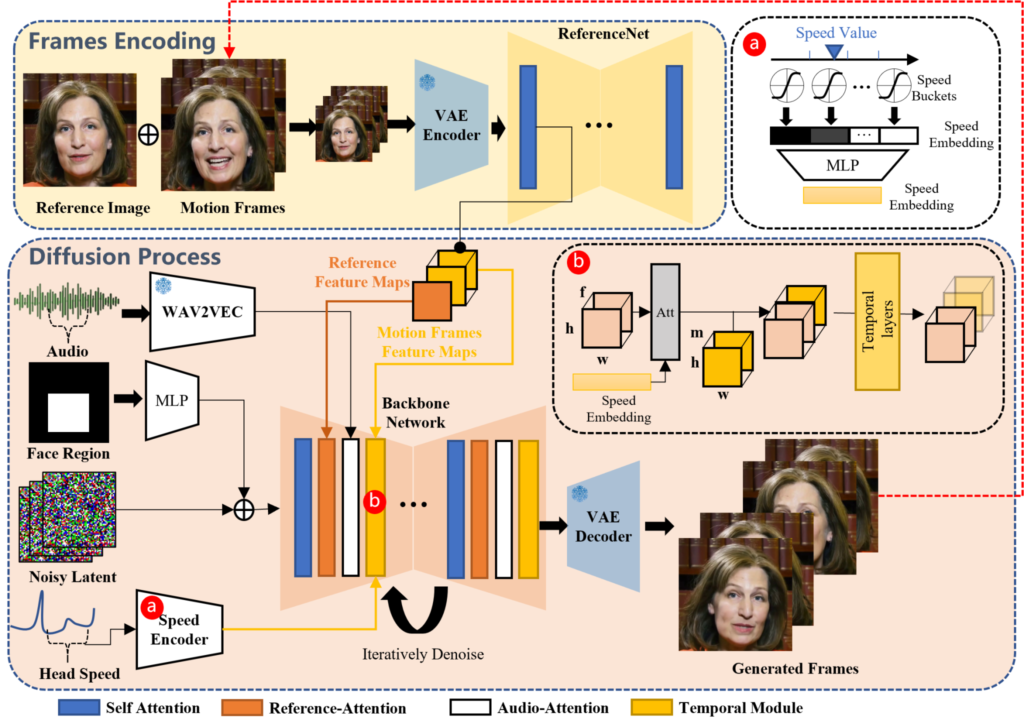
The EMO AI framework by Alibaba operates through a sophisticated two-step process that brings static images to life with remarkable precision and emotional depth. At its core, this process involves frame encoding and a state-of-the-art Diffusion process.
Frame Encoding with ReferenceNet:
In the initial frame encoding phase, EMO employs a component known as ReferenceNet. This tool is designed to meticulously analyze and extract critical features from both the reference image and any motion frames involved. By doing so, it lays the groundwork for creating animations that are not only dynamic but also faithful to the original image’s characteristics.
Advanced Diffusion Process:
The heart of EMO’s technology is its advanced Diffusion process, which is spearheaded by several key components:
Pretrained Audio Encoder:
This encoder processes the audio input, ensuring that the resulting video syncs perfectly with the audio cues.
Facial Region Mask Integration:
This aspect focusing on the facial regions, guaranteeing that expressions are generated with high fidelity and aligned with the audio.
Denoising Operations via the Backbone Network:
Here, the system refines the video output, removing any potential artifacts to produce clean, smooth animations.
Attention Mechanisms:
EMO AI incorporates two forms of attention mechanisms – Reference-Attention and Audio-Attention. These mechanisms work together to maintain the character’s identity consistently across the video while accurately modulating movements based on the audio input.
Temporal Modules:
These modules are tasked with manipulating the temporal aspects of the video, such as motion velocity, to ensure that the generated animations are not just expressive but also seamless.
To further enhance the authenticity of the generated videos, EMO introduces a FrameEncoding module within the ReferenceNet framework. This addition is crucial for preserving the character’s identity throughout the video, adding an extra layer of realism to the animations.
However, seamlessly integrating audio cues with Diffusion Models poses its unique set of challenges, primarily due to the complex nature of translating audio into corresponding facial expressions. EMO tackles this through the implementation of stable control mechanisms, including a speed controller and a face region controller. These controls are vital for maintaining the stability of the video output, ensuring that the animations remain diverse without succumbing to facial distortions or jitteriness between frames.
The Qualitative Comparisons

When examining the effectiveness of various audio-driven portrait-video generation methods, a visual comparison clearly showcases the advancements made by Alibaba’s EMO AI over previous techniques. When utilizing a single reference image as the starting point, certain limitations become apparent in older approaches.
For instance, Wav2Lip often results in videos where the mouth area appears blurred, and the overall head position remains largely unchanged, lacking any sign of eye movement. This can detract from the realism and engagement of the video. Similarly, DreamTalk, while attempting to introduce stylistic elements through supplied clips, may inadvertently alter the original facial features. This can restrict the range of facial expressions and the dynamism of head movements, leading to a less authentic representation.
Source: EMO AI
Results and Performance
In stark contrast, the EMO method demonstrates significant improvements over predecessors like SadTalker and DreamTalk. Its capability to produce a wide array of head movements and more lively facial expressions stands out. Importantly, EMO achieves this heightened level of realism and dynamism without relying on direct signals such as blend shapes or 3D morphable models (3DMM). This not only simplifies the process but also ensures that the animations remain true to the original image’s essence, enhancing the overall viewer experience.
Issues Faced with Conventional Approaches
Conventional approaches to creating talking head videos frequently result in limitations that affect the depth and authenticity of facial expressions. The reliance on 3D models or the derivation of head movement sequences from existing videos may streamline the process, but at the cost of reducing the naturalness of the output. EMO steps in with a groundbreaking framework designed to encompass a wide range of realistic facial expressions while ensuring the fluidity of head movements.
Explore These Videos Created with EMO AI
Discover the Latest Videos from EMO AI:
Cross-Actor Performance
Character: Joaquin Rafael Phoenix – The Jocker – Jocker 2019
Vocal Source: The Dark Knight 2008
Talking With Different Characters
Character: Audrey Kathleen Hepburn-Ruston
Vocal Source: Interview Clip
Character: Mona Lisa
Vocal Source: Shakespeare’s Monologue II As You Like It: Rosalind “Yes, one; and in this manner.
Rapid Rhythm
Character: Leonardo Wilhelm DiCaprio
Vocal Source: EMINEM – GODZILLA (FT. JUICE WRLD) COVER
Character: KUN KUN
Vocal Source: Eminem – Rap God
Different Language & Portrait Style
Character: AI Girl generated by ChilloutMix
Vocal Source: David Tao – Melody. Covered by NINGNING (mandarin)
Make Portrait Sing
Character: AI Mona Lisa generated by dreamshaper XL
Vocal Source: Miley Cyrus – Flowers. Covered by YUQI
Character: AI Lady from SORA
Vocal Source: Dua Lipa – Don’t Start Now
Restrictions of the EMO Model
Here are the Restrictions :
Time Demands:
The approach used by the model comes with its set of challenges, notably its time-intensive nature. This aspect becomes particularly significant when juxtaposed with other methods that do not depend on diffusion models, which tend to be quicker.
Accidental Creation of Extra Body Parts:
A notable drawback of the model is its lack of specific control signals for guiding the movements of the character. This deficiency can result in the accidental production of unwanted body parts, such as hands, leading to inconsistencies in the final video.
To mitigate this issue, one viable strategy could be the introduction of targeted control signals for precise management of each body part’s movement.
conclusion
Alibaba’s EMO AI sets a new benchmark in the creation of talking head videos. Offering a pioneering approach that generates expressive character videos directly from audio inputs and reference images. By leveraging Diffusion Models, incorporating robust control systems, and employing identity-maintaining features. EMO AI delivers outcomes that are both highly realistic and richly expressive. This advancement underscores the significant impact and potential of audio-driven video generation. Positioning Alibaba’s EMO AI as a key player in the ongoing evolution of this technology.
Also Read :-
Introducing Gemma: Google’s New Open Models for AI Development
The Scope of Artificial Intelligence in India
Exploring the Frontiers of AI in 2023: Breakthroughs and Challenges
The Role Of Artificial Intelligence In Education
The Amazing Rise of Claude 2.1: Giving Best AI Potential